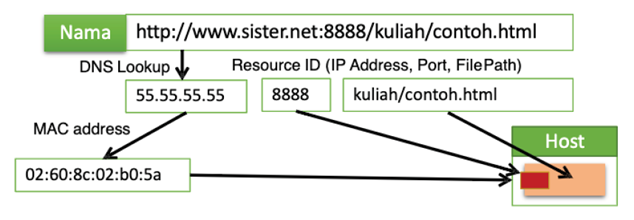
Sebuah nama dalam sistem tersebar adalah sebuah deretean karakter yang digunakan untuk mewakili sebuah entitas. Entitas sendiri dapat berupa secara praktis dapat berarti apapun baik yang bersifat fisik seperti: komputer, printer, media penyimpanan, ataupun modem, maupun yang bersifat abstrak (logic) seperti: berkas (file), user, proses, mailbox, dsb.
Untuk memanfaatkan entitas-entitas dalam sistem tersebar, pengguna (manusia ataupun mesin) perlu mengakses entitas-entitas tersebut melalui sesuatu yang disebut access point, address, atau alamat. Sebuah entitas dapat memiliki beberapa alamat seperti halnya seseorang dapat memiliki beberapa nomor telepon genggam. Contoh lainnya adalah ketika seseorang berpindah tempat seperti kota atau negara maka nomor teleponnya sering harus diubah sesuai dengan sistem di kota (kode area) atau negara.
Jenis nama lain yang mendapat perlakuan khusus selain alamat adalah identifier dengan sifat-sifat sebagai berikut :
- Mewakili paling banyak satu entitas,
- Setiap entitas diwakili oleh paling banyak satu identifier,
- Sebuah identifier selalu mewakili entitas yang sama (tidak berubah menurut waktu dan kondisi).
Satu lagi jenis nama penting adalah nama dengan sifat user-friendly yang mudah dibaca dan diingat oleh manusia. Nama ini biasanya terdiri dari sederetan karakter yang dikenali manusia seperti nama pada file atau nama yang digunakan pada Domain Name System seperti www.unmul.ac.id.
Naming system memiliki beberapa kategori penamaan, antara lain :
- Flat Naming
- Structured Naming
- Atrribute Based Naming
Flat Naming
Adalah penamaan yang tidak memiliki struktur tertentu. Nama dalam Flat Naming terdiri dari sederetan bit karakter yang tidak mengandung informasi tentang bagaimana menemukan alamat untuk entitas yang diwakili oleh nama tersebut.
Teknik Resolving. Ada beberapa solusi dalam menyelesaikan masalah menemukan pasangan alamat/menerjemahkan nama menjadi alamat (resolving) pada sistem penamaan flat naming, yaitu:
- Broadcasting & Multicasting
- Forwarding pointer
- Home-based approach
- Hierarchical search tree
Broadcasting & Multicasting
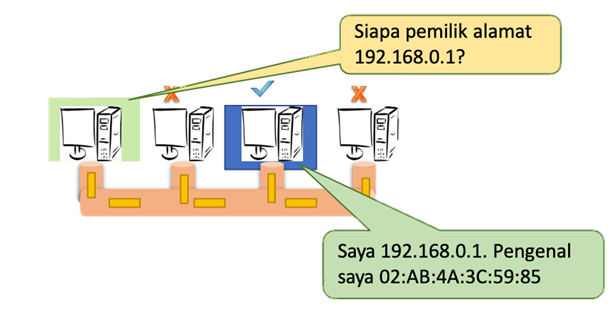
Broadcasting : Mengirimkan sebuah pesan berisi permintaan pasangan identifier dari sebuah alamat kepada seluruh atau sebagian anggota jaringan dan hanya entitas yang memiliki alamat tersebut yang akan menjawab dengan identifier yang ia miliki. Contoh: ARP
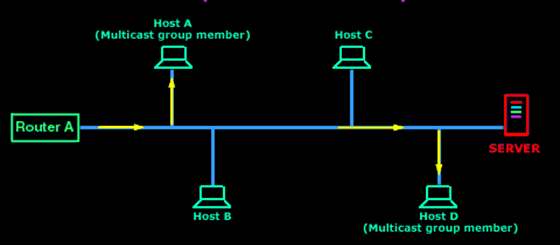
Multicasting : Mengirimkan pesan hanya ke beberapa entitas dalam jaringan. Contoh: Pada unit bergerak seperti laptop milik pegawai yang terkoneksi dengan jaringan nirkabel, membangun group yang membatasi antar unit/divisi.
Forwarding Pointer
Pada teknik ini setiap kali sebuah entitas berpindah lokasi dan mendapatkan alamat baru maka entitas tersebut meninggalkan informasi mengenai lokasi barunya di lokasi lamanya sedemikian sehingga entitas lain yang mencarinya dapat menelusuri jejak perpindahan dan berkomunikasi dengan entitas tersebut.
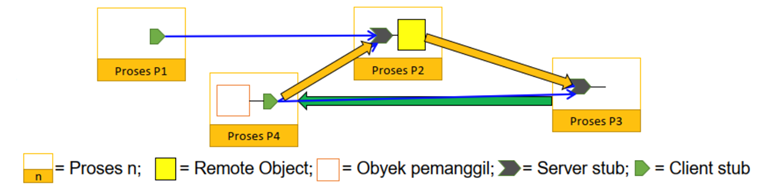
Contoh: Stub-Scion Pair (SSP) Chain
- Menerapkan remote invocations bagi entitas mobile menggunakan forwarding pointer.
- Setiap forwarding poiter diimplementasikan sebagai satu pasangan.
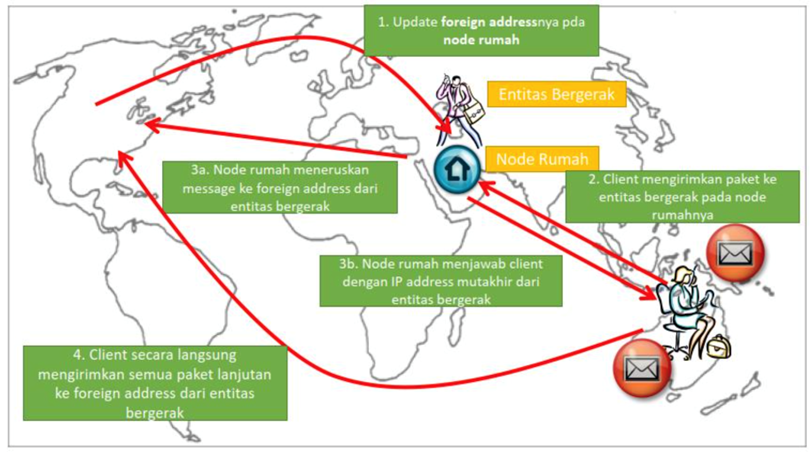
Home Based Approach
Home Based Approch adalah sebuah teknik resolving sedemikian sehingga sebuah entitas bergerak memiliki entitas agen dengan sebuah alamat tetap yang menjadi ‘alamat rumah’. Contoh: Mobile IP Address
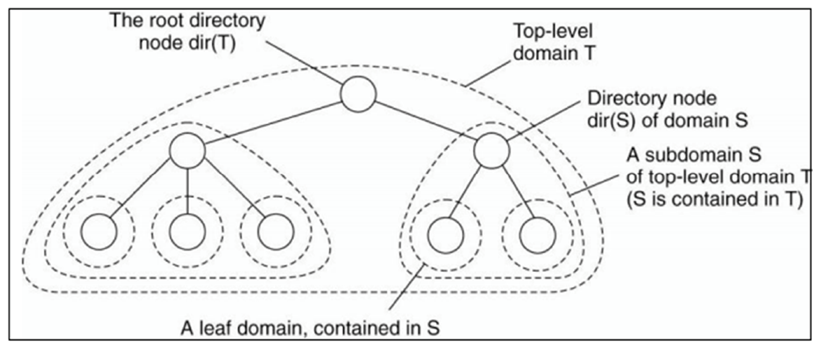
Hierarchical Search Tree
Pada teknik ini jaringan dibagi-bagi menjadi beberapa bagian yang dikenal sebagai domain. Contoh
- Top-level-domain : https://unmul.ac.id
- Sub-domain : https://fkti.unmul.ac.id
- Leaf-domain : https://fkti.unmul.ac.id/visi_misi.php
Structured Naming
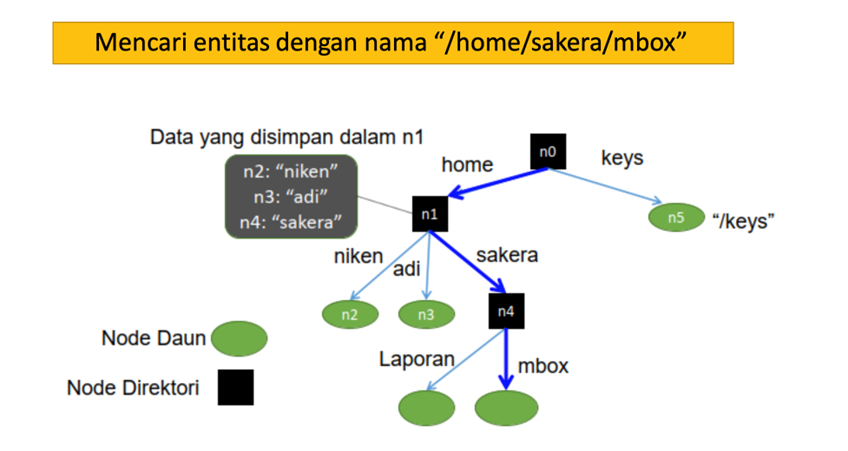
Sistem penamaan biasanya mendukung penggunaan nama yang terstruktur yang dibentuk dari beberapa nama yang sederhana dan mudah dikenali manusia. Name Space : Nama-nama biasanya diatur menjadi sesuatu yang dikenal sebagai ruang nama (name space). Name space untuk nama yang terstruktur dapat direpresentasikan dalam bentuk graph.
Name Space
Ada dua macam simpul pada graph yang merepresentasikan name space, yaitu:
- Simpul daun yang merepresentasikan entitas yang memiliki nama dan tidak menjadi induk dari simpul lainnya
- Simpul direktori yang memiliki ujung-ujung yang bernama dan menunjuk pada dari simpul daun lain.
 Name Space dapat secara efektif digunakan untuk mengaitkan (menghubungkan, membuat link) dua entitas berbeda.
Name Space dapat secara efektif digunakan untuk mengaitkan (menghubungkan, membuat link) dua entitas berbeda.
Dua jenis link dapat hadir antara node-node:
- Hards links
- Symbolic Links
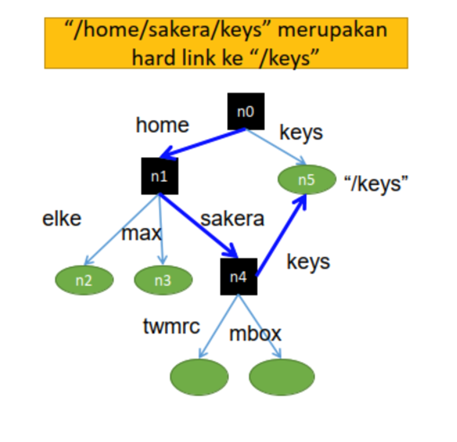
Hard Links
Ada suatu directed link dari hard link (name link) ke actual node (node sebenarnya). Name resolution serupa dengan name resolution yang umum. Aturan yang harus dipatuhi dalam hard links adalah tidak ada siklus dalam graf.
Symbolic Links
Symbolic link menyimpan nama dari node asli sebagai data.
Resolusi nama bagi suatu symbolic link SL:
- Resolve nama SL
- Baca isi dari SL
- Resolusi nama berlanjut dengan isi dari SL
Aturan yang harus dipatuhi adalah tidak diperbolehkan muncul reference cycle.
Name Resolution
Name resolution merupakan istilah untuk proses pencarian (looking up) sebuah nama ketika kita mendapatkan path dari nama tersebut. Proses name resolution ini akan menghasilkan identifier dari sebuah simpul yang dilalui pada proses tersebut.
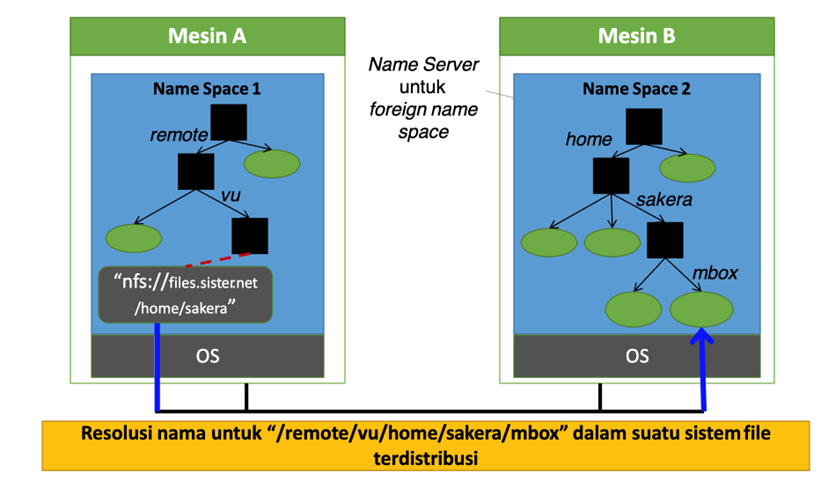
Merged Name Space
Dua atau lebih name space dapat digabungkan (merged) secara transparan dengan suatu teknik yang dikenal sebagai mounting. Dengan mounting, suatu directory node dalam satu ruang nama akan menyimpan identifier dari directory node dari suatu name space lain. Network File System (NFS) adalah contoh dimana ruang nama berbeda digabungkan (mounted)
NFS memungkinkan akses transparan ke file-file remote
Name Space Distributed
Dalam sistem terdistribusi skala besar, penting sekali mendistribusikan name space ke banyak server (name servers).
- Mendistribusikan node-node dari graph name
- Mendistribusikan manajemen name space tersebut
- Mendistribusikan mekanisme name resolution
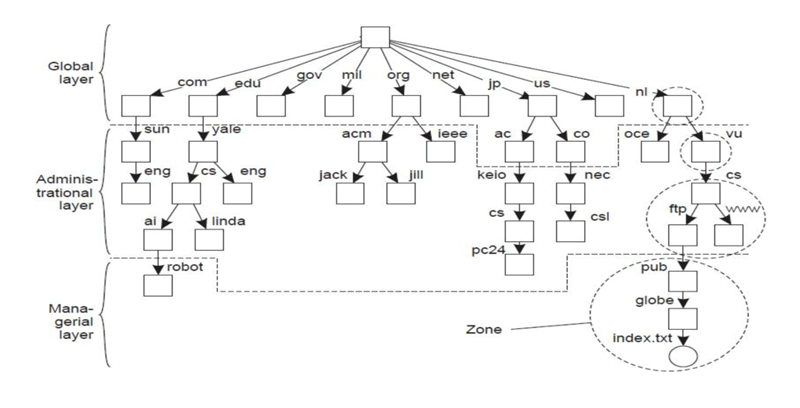
Name Space Distributed Layering
Ruang nama terdistribusi dapat dibagi ke dalam 3 layer:

Contoh: DNS
Name Resolution Distributed
Name Resolution Distributed bertanggung jawab untuk memetakan nama-nama kealamat dalam suatu sistem dimana:
- Server-server nama didistribusikan antar node-node yang berpartisipasi
- Setiap server nama mempunyai suatu name resolver lokal
Ada dua algoritma resolusi nama terdistribusi:
- Interactive name resolution
- Recursive name resolution
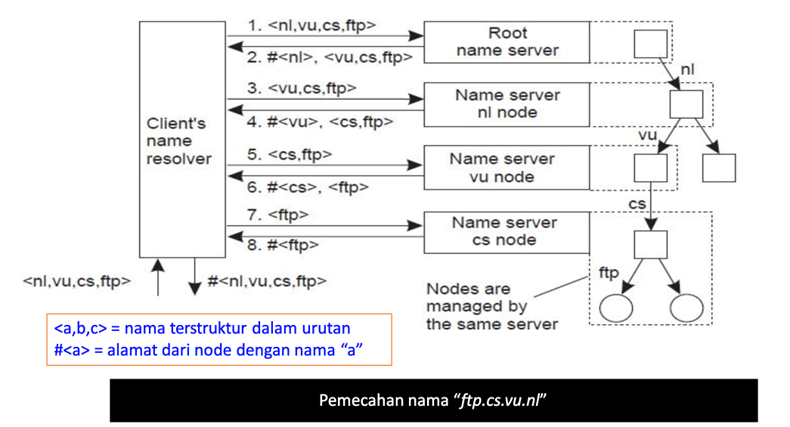
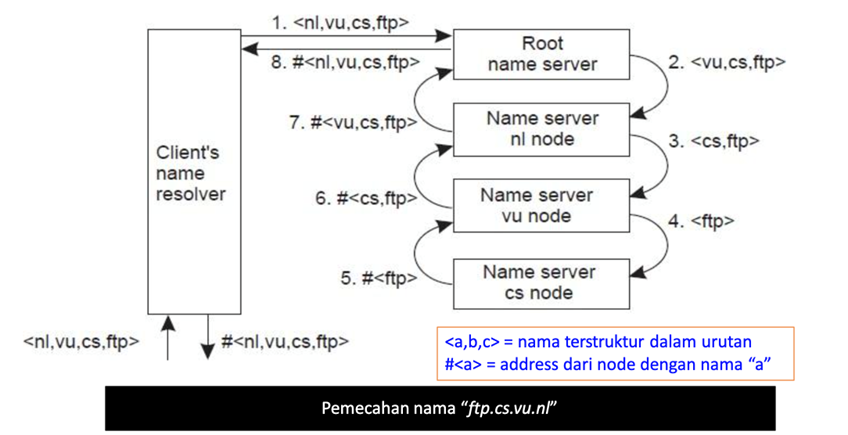
Interactive Name Resolution
- Client menyerahkan nama lengkap yang akan dipecahkan ke root name server.
-
Root name server memecahkan (resolve) nama sejauh kemampuannya dan mengembalikan hasilnya kepada client.
Root name server juga mengembalikan alamat dari server namalevelselanjutnya (disingkat NLNS) jika alamat tidak terpecahkan secara lengkap.
- Client melewatkan bagian yang tidak terpecahkan dari nama ke NLNS
- NLNS memecahkan nama sejauh kemampuannya dan mengembalikanhasilnyakepada client (bersama dengan next-level name server-nya)
- Proses ini berlanjut sampai nama lengkap terpecahkan
Recursive Name Resolution
- Client menyerahkan nama yang akan dipecahkan kepada root name server.
- Root name server tersebut melewatkan hasilnya ke next name server yang ditemukannya.
- Proses berlanjut sampai nama tersebut secara lengkap terpecahkan.
- Memiliki kekurangan biaya besar pada name server (terutama pada server nama tingkat tinggi).
Attribute Based Naming
Seiring bertambahnya informasi yang dapat diakses dari sebuah entitas maka diperlukan sebuah cara agar pengguna dapat mencari dan mengakses suatu entitas dengan memberikan keterangan mengenai entitas. Salah satu cara yang populer adalah menggunakan attribute based naming (penamaan berbasiskan atribut). Dengan teknik ini sebuah entitas diasosiasikan dengan sejumlah atribut yang memiliki nilai tertentu.
Pengguna melakukan pencarian berdasarkan kriteria tertentu berupa jenis dan nilai atribut yang dimiliki entitas yang dicarinya. Sistem penamaan berdasarkan atribut lebih sering dikenal sebagai directory service sedangkan sistem penamaan terstruktur lebih dikenal sebagai naming System. Pada directory service entitas memiliki beberapa atribut yang dapat digunakan sebagai kriteria pencarian.
Contoh: Light-weight Directory Access Protocol (LDAP)
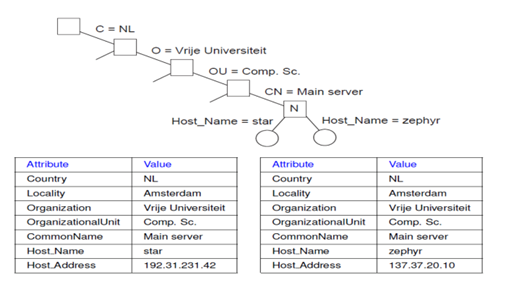
LDAP
Layanan direktori LDAP terdiri dari sejumlah record bernama “directory entries”.
- Setiap record tersusun dari pasangan (attribute, value).
- Standard LDAP menetapkan lima atribut untuk setiap record.
Directory Information Base (DIB) adalah koleksi semua directory entries.
- Setiap record dalam DIB bersifat unik.
- Setiap record direpresentasikan oleh suatu nama yang membedakan.
Directory Information Tree LDAP
Semua record dalam DIB dapat ditata ke dalam suatu pohon hirarkis bernama Directory Information Tree (DIT). LDAP menyediakan mekanisme pencarian lanjut berdasarkan pada atribut dengan melintasi DIT tersebut. Contoh sintaks untuk pencarian semua Main_Servers di dalam Vrije Universiteit:
search("&(C = NL) (O = Vrije Universiteit) (OU = *) (CN = Mainserver)")